此文档总结一些易忘记和易混淆的基础概念。
顶层const与底层const
顶层const是指任意对象是const,而底层const指的是指针或引用的基本数据类型是const。
简单来说
1 | const int a = 1; // 顶层const |
大端和小端存储方式
大端方式:高位字节放在低位地址。
小端方式:低位字节放在高位方式。
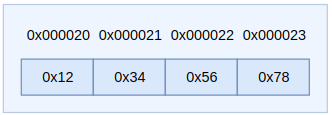
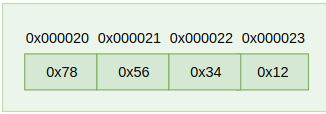
对于16进制数0x12345678,大端方式存储时内存分布如图1(左边),小端方式存储如图2(右边)。
对于大端方式来说,从地址0x000020到地址0x000023依次存放着0x12,0x34,0x56,0x78;而小端方式则相反,从地址0x000020到地址0x000023依次存放着0x78,0x56,0x34,0x12。
大端和小端方式的检测
方法一
先说一下思路,首先主机字节序有上面说的两种,大端和小端方式。而网络字节序是规定好的,只能是大端方式,因此可以通过比较一个按照主机字节序存储的变量和一个按照网络字节序存储的变量。
函数htonl用于将数据从主机字节序转为网络字节序。其中h代表主机(host)字节序,n代表网络(network)字节序。另外,l指的是long(Linux中long类型占用4个字节,这很关键)。
1 |
|
运行结果
在我的64位机器上运行结果,可知,我的机器是以小端方式来存储数据的。以大端方式存储时,
$$
0x12345678 = {8} \times {16^0} + {7} \times {16^1} + {6} \times {16^2} + {5} \times {16^3} + {4} \times {16^4} + {3} \times {16^5} + {2} \times {16^6} + {1} \times {16^8}
$$
结果为305419896;而以小端方式存储,16进制数0x78563412转为10进制,结果为2018915346。
1 | sizoef(a):4 |
方法二
上面是通过调用htonl函数来得到一个以大端方式存储的数据,我们也可以手动创建一个以大端方式存储的32位数据。
1 |
|
运行结果
可以看出这里手动创建的32位数据(大端方式存储)和上面经过网络字节序转换之后的一样。
F()和F1()两个函数是等价的,两个函数实现的同样的功能。唯一的不同是,在F()使用的是旧式类型转换,而在F1()中则使用了新式类型转换。
另外,在使用新式类型转换时,无法使用static_cast,而能够使用reinterpret_cast,这是为什么,还没弄明白。
1 | a=2018915346 b=305419896 |
关于类型转换的更多知识,请自行查看类型转换系列1。
二叉树的高度和深度
根节点到任一节点的路径长度,即该节点的深度。根节点的深度是0。
某个节点即其最深叶子节点的路径长度即高节点的高度。叶子节点的高度为0。整棵树的高度即根节点的高度。
参考文献
[1]TCP/IP网络编程(尹圣雨著)